
Total Engagement in a Nutshell
Today we officially released Total Engagement. You can read the press release here.![]()
Q: What is Total Engagement? Give me the elevator pitch.
A: Our Total Engagement release is comprised of two parts;
i) We now support analytics for Mobile Apps – meaning that we collect and report app user events
ii) we combine app usage measurement with traditional web reporting. As far as we know, we are the only company on the market who can display app user eventstreams and website visitor clickstreams in the same report on the same page.
Q: What does that actually mean?
A: That means that if you make or publish apps and websites you can see all activity in one place, in realtime.
Q: How cool is that?
A: Very cool!
Q: Do you have a PDF that explains all that to me with visuals so that I can read it for myself?
A: Yes, click here.
How to Run Google Ads
CONTENTS
- Vocabulary
- What are Google Ads
- Setting Up Your Ad
VOCABULARY
- Objective – What you want the ad to accomplish
- Keyword – a google search that is related to your product (what a customer might type to find your product)
- CTR (Click-through-rate) – the percentage of people that click on your ad after seeing it
WHAT ARE GOOGLE ADS?
Google Ads, formerly known as Google Adwords, is an online advertising platform. Google ads can work for any product or service because people search Google for almost any and everything.
One strong suit of Google Ads is that the system is centered around showing your ads to people who are ALREADY looking for a solution that your product or something similar will offer, as opposed to a lot of other forms of advertisement that may show it to people way outside your target audience.
The pricing system is pay-per-click (PPC). This means that you do not pay except the ad actually gets people to click on it and get to your chosen landing page/website. You can set your maximum bid for each click (Google Ads pricing works with a bidding system) and Google Ads will not spend more than that from your account. Payment could be CPC cost-per-click, CPM (cost-per-mille i.e. cost per 1000 impressions) or CPE (cost-per-engagement).
Google Ads, generally, averages an 8% click-through rate. With almost 250 million different visitors and about 700 million dollars return on investment from the 2.3 million searches that Google gets every second, you can be sure that there are a lot of potential customers on the platform for your brand or business. The exception is that Google Ads does not support ads for products or services that are:
- Dangerous e.g. weapons, recreational drugs
- Inappropriate or offensive e.g. bullying and racial discrimination
- Advocative of dishonest practices e.g. hacking software, fake documents
Types of Google Ads
There are five different types (also called campaigns) of google-ads namely:
1. Search: These are the types, in text form, you see at the top of the result page when you make a google search. Ads can also be created to appear in Google Maps.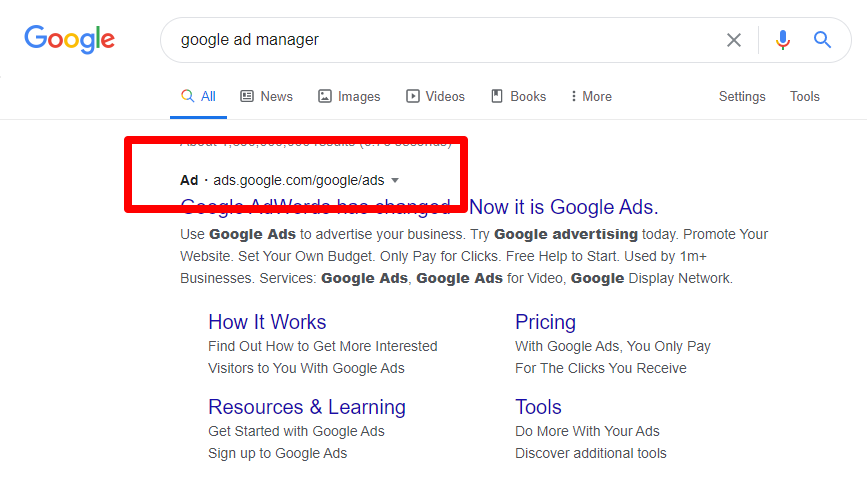
2. Display: These show up on Gmail and other websites that are a part of the GDN (Google Display Network) like youtube, gmail. etc. alongside relevant content, Google Display Networks have 180 million impressions per month.
3. Shopping campaigns: These can show off your products with images and include links to your business page.

3. Shopping campaigns: These can show off your products with images and include links to your business page.
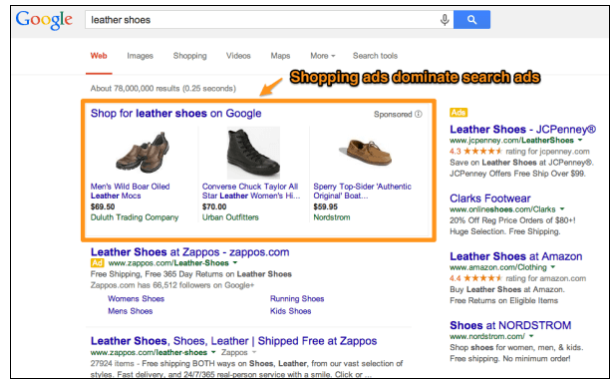
Source: Search Engine Land
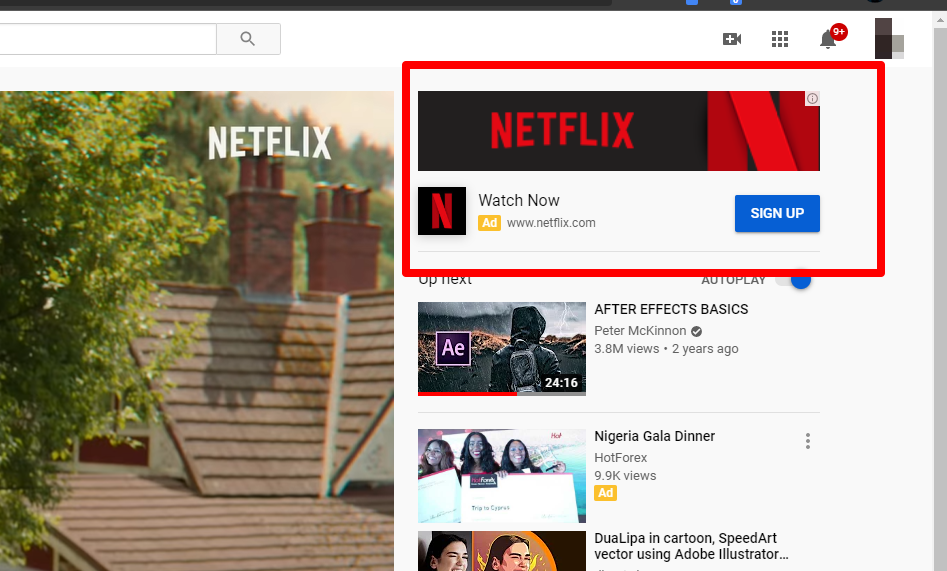
4. Video: Ads shown on YouTube by the side bar and also placed when playing videos.
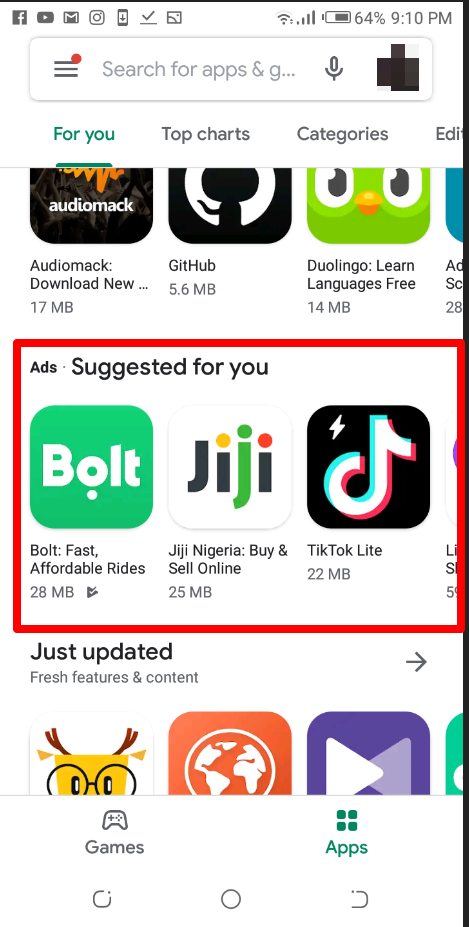
5. App: These promote your app on Google Search, YouTube, Google Play and other platforms to advertise to the right people.
Objectives of Google Ads
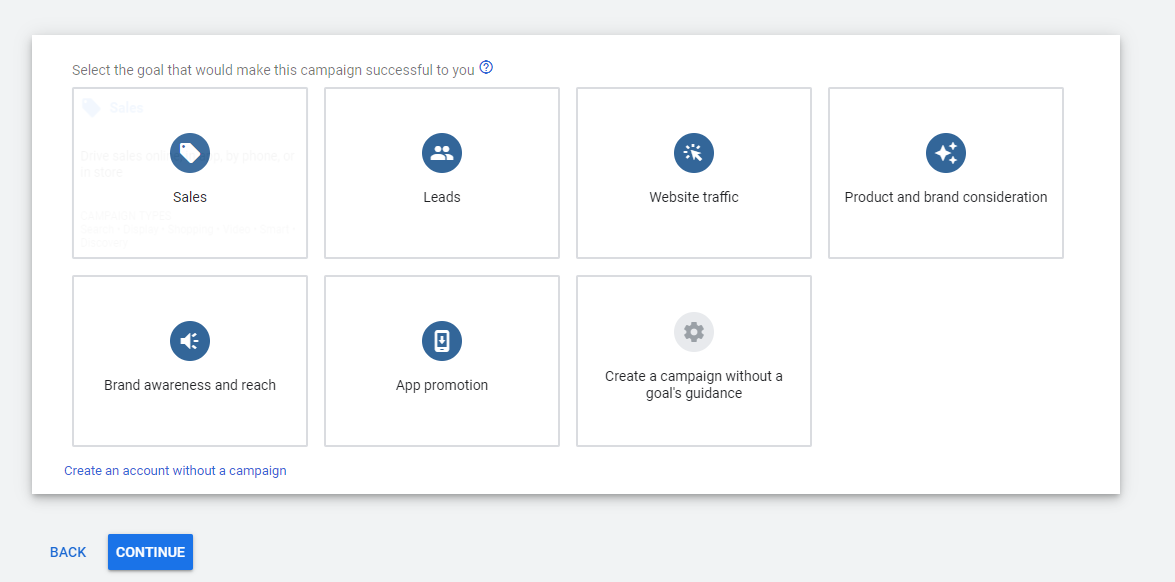
You can choose the goal you want to accomplish for your brand from the list of laid out objectives that will be shown to you in the process of setting up your ad. This list is comprised of the following:
- Sales
- Leads
- Website Traffic
- Product and Brand Consideration
- Brand Awareness
- App Promotion
SETTING UP YOUR ADs
There are 3 stages to setting up your Google Ads Ad:
- Create Campaign
- Create Ad group
- Create Ad in Ad Group
Before you start creating your campaign, it’s best you do some research on the most effective keywords for your niche.
There is a tool in Google Adwords that can help you do this, but you must have created your first campaign to have access to it. It’s called ’Google Ads Keywords’.
You can create a campaign, use the Keyword Planner and then edit your keywords for that ad. However, sites like keywords.io, ahref can help you with this before your first campaign is created.
- You must have a Gmail address to run a Google Ad.
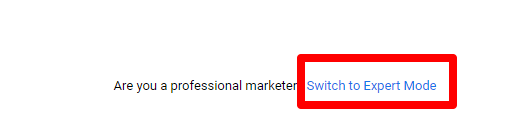
- Go to Google Ads.com and click ‘Start Now’ at the top right corner of the page.
- At the bottom middle, click on “Switch to Expert Mode”
i. You’ll see an outline of different objectives. Select the one that is most relevant to you. For This example, ”Website Traffic”
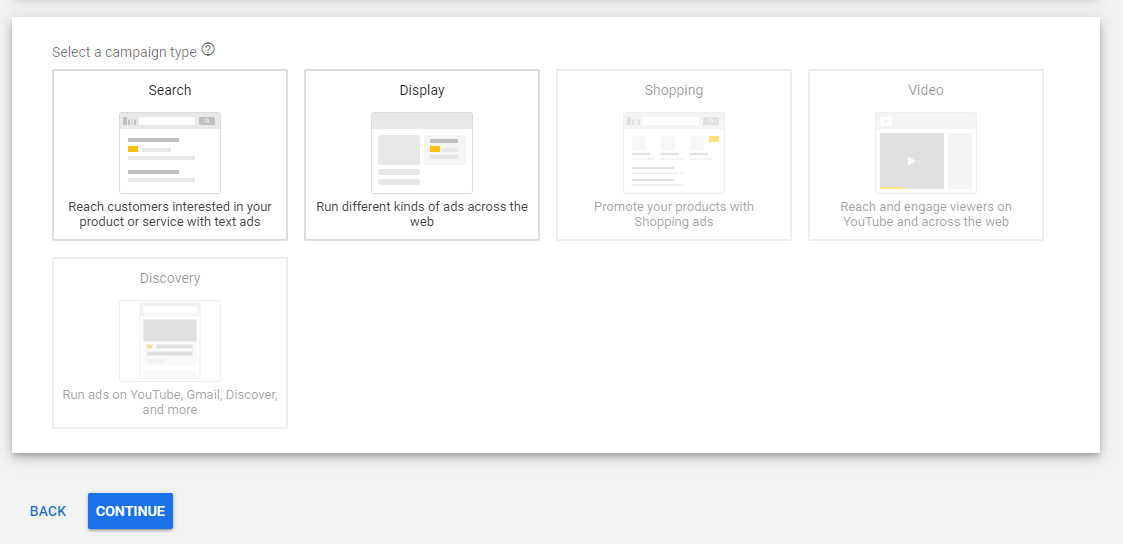
a. Select web-site traffic.
b. Select the type of ad you want to run e.g. ‘search-based’
c. Input your website
d. Click continue.
e.Create your campaign
- Name your campaign (this won’t show on the ad)

- Deselect ‘search-network’ and ‘display-network’ if you don’t want your ad shown on the sidebar of other websites outside Google. Since Google seems to be more effective than its search partners, unchecking this box should save you some money.
- Set your start-date and end-date. If you don’t set an end-date, the ad will continue to run and you will continue to be charged.
- Select the location(s) where you want people to see your ad e.g. your country. (the more specific you are, the more the ad might cost you).
- Name your campaign (this won’t show on the ad)
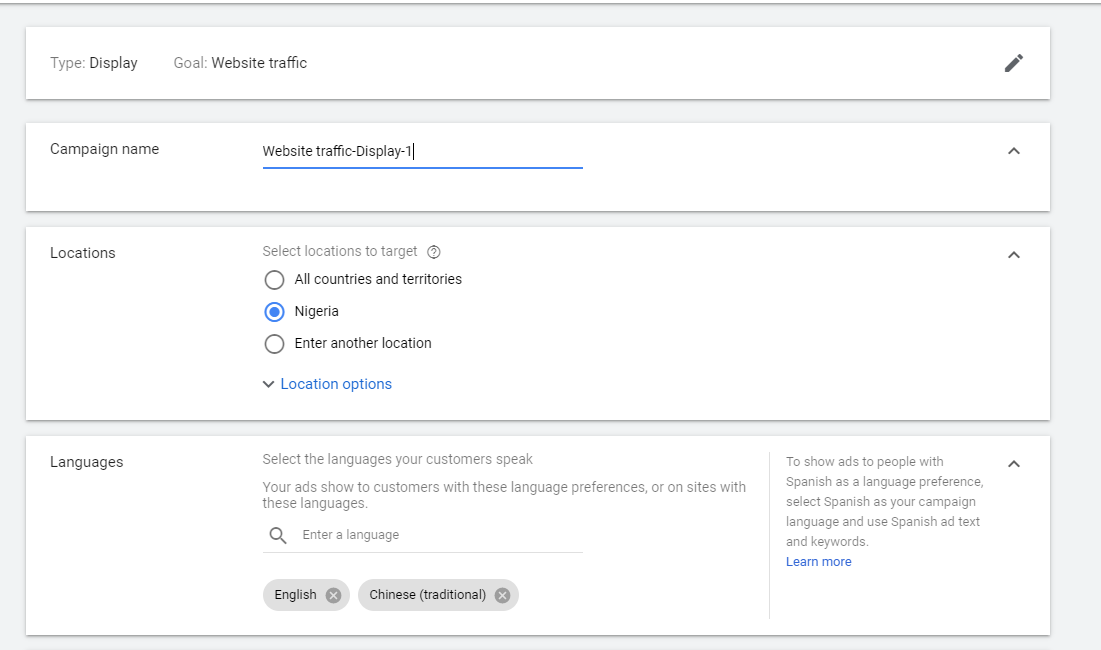
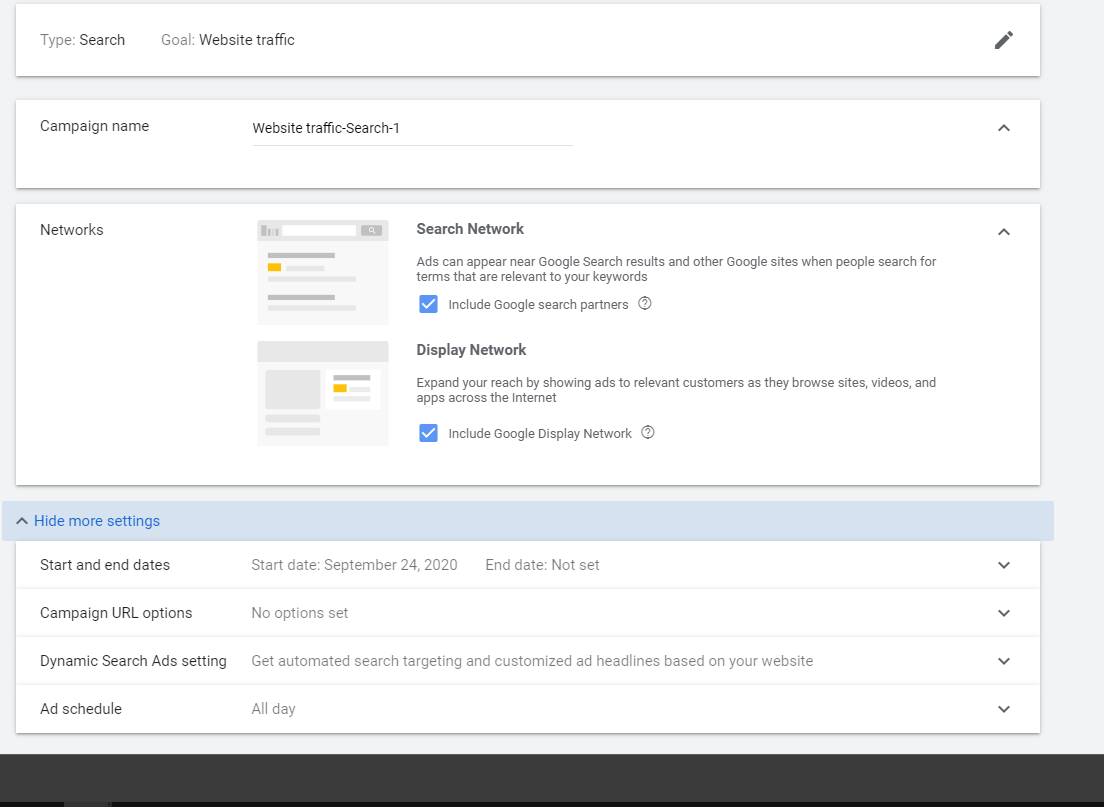
Instead of typing in a specific location, you can also set the ad to run within a specific-mile radius from a particular point e.g. a 30-mile radius from your store.
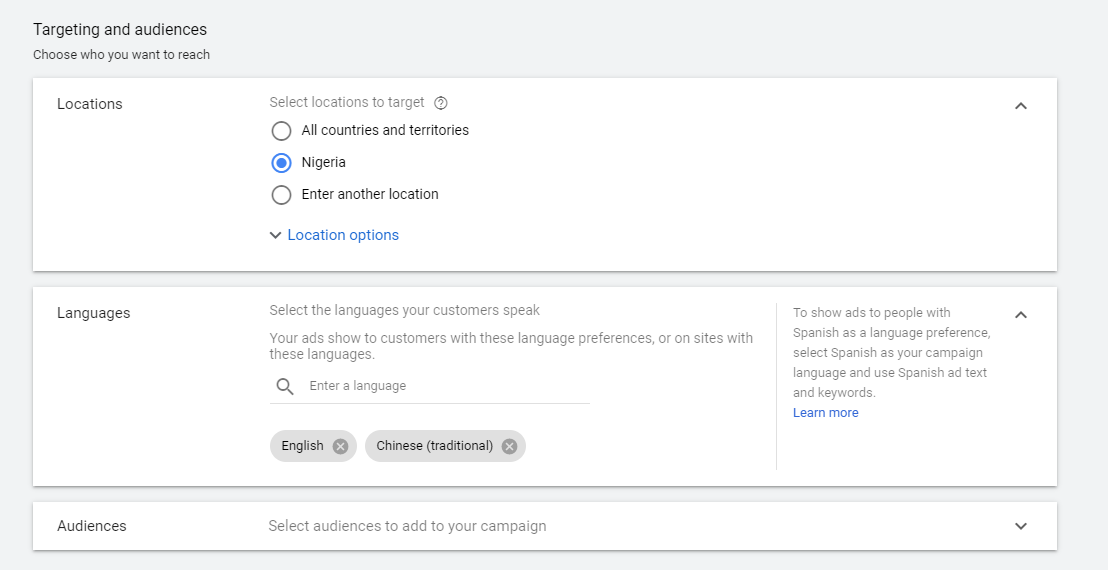
- Select the language you want your ad displayed in.
- Set your budget. You can start small and see how effective the ad is.
A very low budget like 1USD per day might not give you an accurate representation of how effective Google Ads is for your business because it is likely to afford you just a couple clicks.
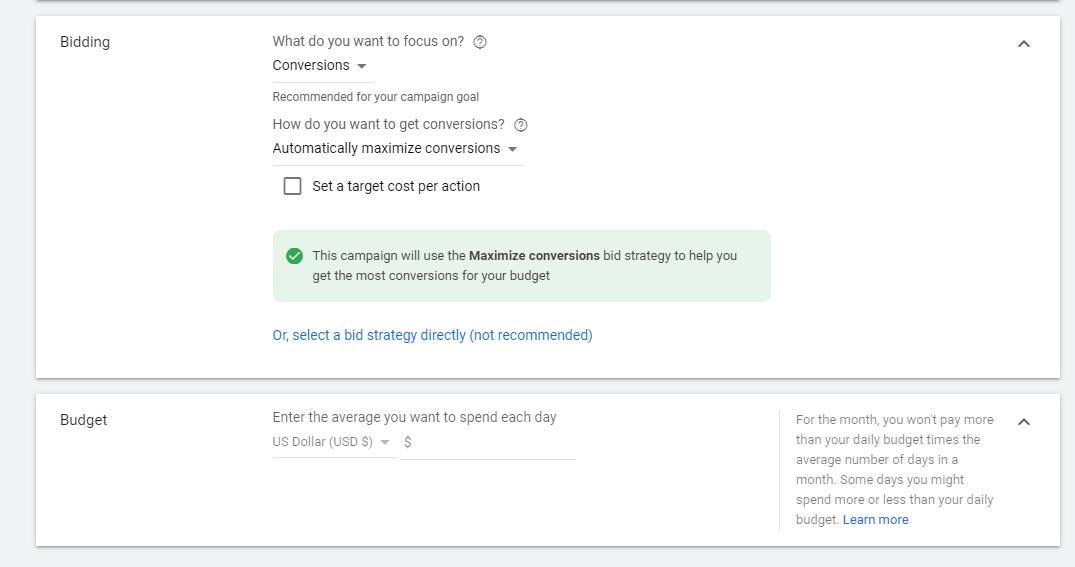
You can set a maximum CPC. You can also experiment with this and see how it works .
Choosing accelerated means Google will spend your budget as quickly as possible, Standard means your budget will be spread over the course of your ad’s lifespan.
In additional settings, you can do things like set a time schedule for your ad to run, if you want it to run for specific periods during the day. You can also add more business information and your prices to your ad, amongst other things.
- Click ‘Save and Continue’.
f. Create an Ad Group
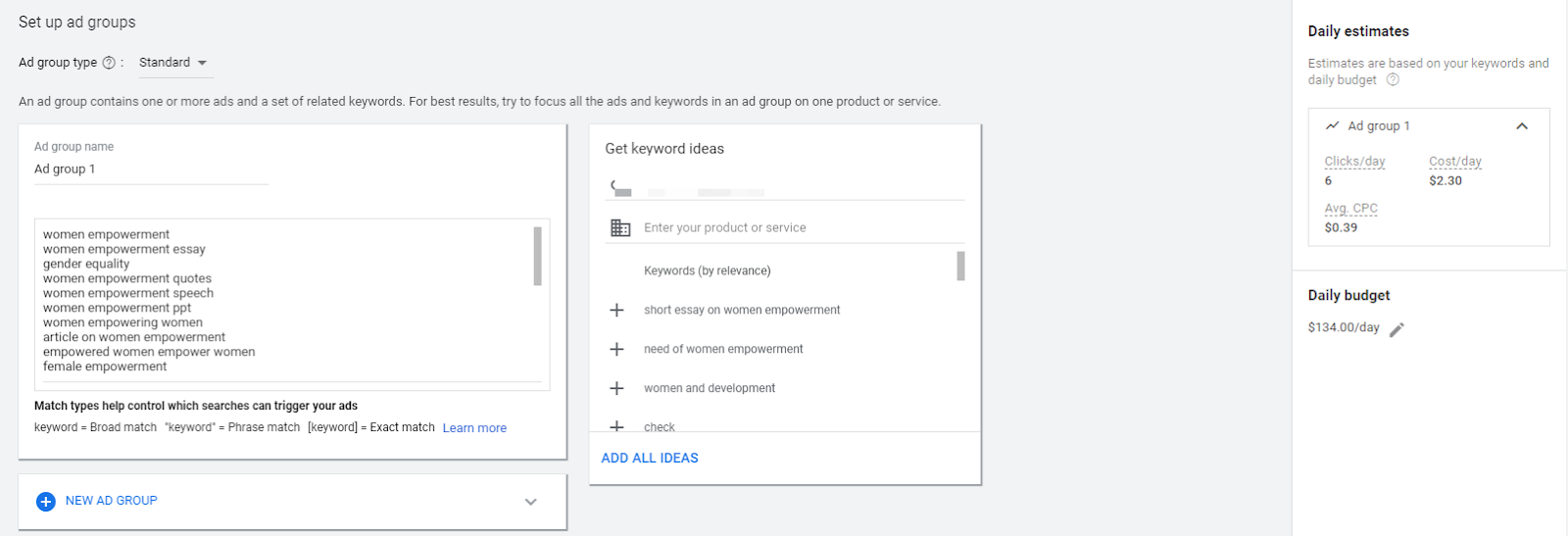
- Name your ad group (this won’t show up on the ad itself)
- Enter the phrases/keywords you want to trigger your ad. Once you have set up your account (which we’re doing right now), you’ll have access to Google Keyword Planner which will help subsequently in helping you choose the most precise and profitable keywords for your product or service.
There are also other tools that you can use to take the guesswork out of the game, even for your first attempt e.g. keywords.io
In inserting your keywords, you can type it in 4 different formats for 4 different effects, these effects are called ‘matches’.
- Broad match: If you enter your keywords in this format: dresses for babies, it will give a broad match to those words and anything related e.g. baby clothes, baby things.
- Modified broad match: In this format, you put the plus sign before words that you want to be in the Google search mandatorily e.g. +baby clothes (if someone searches ‘infant clothes’, the ad won’t show up) or baby +clothes (if the user types in ‘baby apparel’, the ad will not come up.
- Phrase match: If you enter the keyword in quotation marks like so “dresses for babies”, it’ll give a narrower match to google searches that contain that exact phrase e.g. if someone searches ‘dresses for baby’, your ad won’t show up but if someone typed ‘colorful dresses for babies’ or ‘dresses for babies discount’, your ad will be displayed.
- Exact match: Entering your keyword in square brackets allows a match with the exact phrase and no other additional word. It has been modified to include searches with synonyms or reordered phrases e.g. if your keyword is [dresses for babies], it will match with searches that say ‘dresses for babies’, ‘dresses for infants’, ‘babies for dresses’.
Each keyword can be entered in multiple formats in one ad, if you so wish, for any reason.
A column on the side will show you an estimate of how many clicks you could get with those keywords and how much it would cost you.
- Click ‘Save and Continue’.
g. Create Ad
- You can use split-testing and split your budget between multiple ads under one ad group so you can see which one works best and continue to use that one in the future.
Tip: Make sure to assign tangible amounts of money to each ad so you can get an accurate reflection of its effectiveness.
- Insert your 2 headlines. Try something catchy, maybe add a
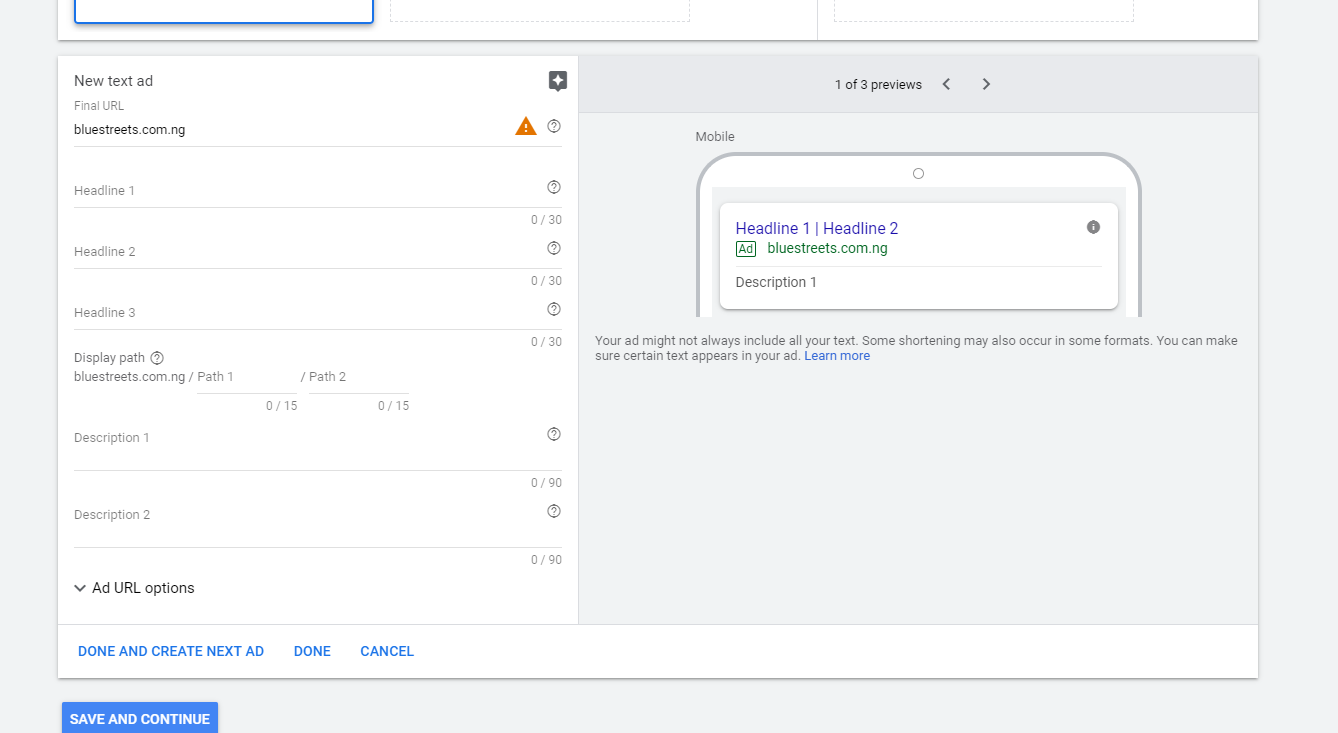
discount to the second headline.
- Insert your descriptions.
- Save and Continue.
- Insert payment info and if you have a promo code, insert that also.
- Submit.
Congratulations! You just created your first campaign.
Tools to optimize your Google Ad:
- Now that you’ve set up an ad, you can make use of the Google Keywords Planner Tool to optimize your ads.
Click on explore your campaign.
To create a new campaign, go to All Campaigns” and click on the plus sign.
- Monitor the insights that Google Ads gives you on how well ads are doing. This will help you understand what’s working and what’s not so you can further optimize your ads in the future and gain more bang for your buck.
- Negative keywords: These stop your ad from being shown in search results if someone uses certain words along with your keywords e.g. discount or babies if you don’t give discounts or sell clothes only for adults. It also stops Google from bidding your set price/budget against the advertisers that want to use that/those keywords.
- Click on keywords
- Add negative keywords
- Save
You can also create a negative keywords list to use in the future by clicking ‘Explore Campaign’, then ‘Tools and settings’ then Negative keywords list. When you’ve named it and created the list (it can be one or two words long), click on it, then click on “Apply to Campaigns’ to apply it to all or some of your campaigns.
Tip: You can use Ubersuggest.io to find negative keywords for your brand
- Google keyword planner:
- Click Explore Campaign
- Click on tools and settings at the top-right corner of your screen
- Click Keyword Planner. Two bars will come up.
- Google keyword planner:
-You can use the first to find new keywords, see how much each will cost you, how much competition each keyword has (you want to pick the ones with low competition but relatively high searches; compared to others on the list).
-The second bar will help you see potentially how well your ad might do -this will help you ‘discover new keywords’ that you can use and see how well existing keywords do for other ads e.g. the CPM (cost per 1000 impressions).
- When you click on a particular campaign, you can change certain settings like what types of devices your ads are shown on by clicking the tab that says ‘devices’ on the lower left portion of the screen. Selecting the most likely option for your business removes the risk of your budget being used to show your ad on devices that are irrelevant to your business.
THINGS TO NOTE:
- You can choose to pause or even stop your ad at any point in time you so wish. You can even adjust your budget after it starts running.
- One campaign can have more than one ad group and one ad group can have more than one ad in it
- The more clicks you get, the less your CPC becomes.
- if you will be creating a large number of campaigns, you can use an app/tool called ‘Google Adwords Editor’ to help you out with managing them.
- If you’re managing multiple accounts for multiple clients, you need to first create a managers account.
You can then create your clients’ accounts under that and start from there. You can use one email for both the manager s account and up to 20 client accounts.
- To track conversions, you need to define what a conversion is to you: leads, sales, signups, phone calls from your settings. This will help you know which ad is working and which is not, know what time of day your ads are most effective etc.
Conclusion.
Remember Google shows your ad to who is looking for you. You have the ability to advertise to individuals that want to find you. This step-by-step guide covered the necessary knowledge you need to have before, during and after creating your first google ad. From Knowing the types of google ads, creating your campaign account, drafting your ad, picking a suitable keyword to tracking and measuring your first google ads.
How to Incorporate Social Media into Your Buyer Journey
What was once a place to connect with friends has become an integral part of any marketing toolkit. In 2023, spending on social media advertising is expected to reach $268.7 billion, and with good reason. From building brand awareness to fostering engagement, social media has proven to be a powerful part of the customer journey.
But social media is about more than just scheduling content and increasing your brand’s visibility. It’s about understanding your customer and their unique journey. By taking the time to anticipate their needs, you can position your product or service as the natural solution to their problems.
Here’s how you can utilize the opportunities social media offers in each stage of the buyer journey and integrate social media conversion tracking into your ecommerce dashboard.

Incorporating Social Media into Each Stage of the Buyer Journey
Awareness Stage
Social media is proven to be a vital tool in driving brand awareness. By creating relevant and engaging content, your brand can capture the attention of potential customers while amplifying the reach of your other marketing efforts (such as public relations or content marketing). The goal here is to choose platforms where your audience is most likely to be found and then create awareness campaigns tailored to those platforms. Social listening on Facebook groups, for example, will give you insight into what topics your audience is most interested in and allows you to create content that resonates with them in a powerful way. Giveaways and competitions are also effective ways to get people engaging with your brand and build a following.
Consideration Stage
By sharing product demos, customer testimonials, and reviews on your social media channels, you can provide potential customers in the consideration stage with the information they need to make an informed decision. In addition, you can utilize social media to answer any queries or concerns potential customers may have. Q&A live sessions, for example, are an excellent way to engage with your audience and provide real-time support. Unboxing videos and product reviews can also be highly effective in providing customers with the confidence and motivation they need to make a purchase. If you offer a guarantee, now is the time to promote it. But, always ensure that your promotional posts have an authentic and customer-centric tone. A direct-to-camera video, for example, can be a great way to make a personal connection with your audience and put a human face to your brand.
Conversion Stage / Decision Making
The power of social media lies in its ability to reach a massive audience, and businesses can leverage this to offer exclusive deals to their followers. By promoting offers, discounts, and other incentives on their social media channels, businesses can create a sense of urgency and drive customers to convert. Posting thought-leadership content and authority-building content at this stage in the journey is essential to position your business as a trustworthy leader in the market. Strong calls to action in captions and interactive videos where buyers can purchase directly through your video are great ways to leverage the power of social media to drive sales and increase conversions.
Retention Stage
The sense of community that social media provides is invaluable in retaining customers. By fostering a two-way dialogue on social media, businesses can create meaningful relationships with their customers, boosting retention rates. This means posting consistently on whichever platforms you have chosen as your best fit, engaging with customers directly, and responding swiftly to their queries. Offering repeat buyer discounts or loyalty programs can also be a great way to encourage customers to come back and purchase with you again. Additionally, by tracking customer journeys on social media, businesses can better understand their purchasing habits and tailor relevant content to each individual. This ensures that customers feel appreciated, valued, and understood — critical factors in the customer experience.
Advocacy Stage
When businesses share user-generated content, such as customer reviews and testimonials, they can showcase their happy customers and create a ripple effect of positive sentiment. Ultimately, this can lead to increased customer loyalty and higher conversion rates. User-generated content is far more impactful than any other type of content as it is authentic, unbiased, and highly trusted by potential customers. One way to encourage user-generated content is to run competitions and reward customers who share your content on their own social media channels. Using a branded hashtag and motivating customers to mention your hashtag in posts is a great way to increase awareness of your brand and can be incredibly effective in increasing consumer engagement. Partnering with influencers and micro-influencers is also an excellent way to leverage social media for advocacy and generate positive sentiment around your brand. Well-chosen influencers can help to spread the word about your products and services, further exposing your brand to potential customers.
Pro Tip:
By posting one of these above-mentioned content pieces daily, you’ll have enough content to post five times a week. This way, you can consistently and effectively reach the full spectrum of your buyers at different stages of their journey.
Measure the Impact of Social Media on Your Buyer Journey
Many social media platforms have built-in analytics tools that allow you to track your impressions and engagement. But what if you want more robust tools that integrate with your e-commerce site to track your conversion rate?
For many businesses, the challenge lies in translating advertising budgets into meaningful conversions. While brand engagement, sentiment, and reach are critical, they should be seen as a bridge from your social campaigns to your website.
At Opentracker, we provide the essential tools you need to identify which marketing channels are driving the most traffic, along with key metrics such as page views, cart additions, and conversions that provide valuable insights into how customers interact with your site. This, in turn, allows you to improve everything from your checkout process to your user interface to streamline the customer experience.
Tap into the full potential of social media marketing with goal-oriented customer journey tracking! Click to book a discovery call today!
The Role of Mobile in the Modern-Day Customer Journey
It’s no secret that the rise of smartphones has transformed how people interact with brands. Whether it’s the latest in fashionable footwear, browsing product reviews, scouring real estate listings, or making dinner reservations, you’d be hard-pressed to find an industry that hasn’t overhauled its customer journey in response to the breakneck pace of our mobile-first world.

[Photo by Luis Villasmil on Unsplash]
The convenience of mobile devices has revolutionized how customers research, compare, and ultimately, purchase products and services. With the rise of mobile apps, social media, and mobile-responsive websites, businesses can gain meaningful insights into their audience while delivering a personalized customer experience that fosters engagement, connection, and conversions.
By harnessing the power of a mobile-centric customer journey, ambitious businesses can enhance their overall marketing and sales strategies—here’s how.
Awareness: Mobile Boosts Business Discoverability
As a result of the rise of mobile search, new businesses are being discovered at faster rates than ever. In addition to search engines like Google, potential customers are leveraging various platforms to uncover products and services in their area.
This includes platforms that were not initially created for search, such as TikTok, Facebook, Instagram, YouTube, and Pinterest. Today, some customers discover new products solely through these apps, foregoing traditional search engines altogether.
With so many avenues for customers to meet your brand, businesses that fail to embrace mobile risk being overshadowed by competitors. Today, a comprehensive marketing strategy not only requires ensuring high visibility on Google, but also means having a strong presence on social media and listing directories, tracking your customers on multiple platforms, and effectively following up on leads.
Conversions: Mobile Revolutionizes How Customers Buy
A decade ago, customers would take the time to search for a solution to their needs, seek out credible reviews, compare prices on various e-commerce sites, and check out a business’s website. Today, that process happens lightning fast—in a few minutes, and often without leaving their search platform.
In the fast-paced world of e-commerce, optimizing the mobile customer journey is essential for any business that wants to remain competitive. If your customers are finding you on search or social media platforms, implementing native tools (such as Google Shopping or Instagram Shopping) provides a frictionless shopping experience that makes it easy for them to navigate to their cart and complete their purchase.
Of course, identifying where and how your customers are shopping is key to improving your customer journey. Whether your customers are shopping on Amazon, eBay, Google, or other e-commerce platforms, we keep track of your customer data from multiple sources in one place to give you a complete overview of your performance on each channel.
Retention: The Mobile Experience Brings Customers Back
The mobile-first customer journey doesn’t end with a purchase. A great mobile user experience can facilitate long-lasting relationships with loyal customers by providing fast and efficient shipping status updates, streamlined package tracking, and robust after-sales support.
To further enhance the post-purchase customer experience, mobile retargeting is a powerful tool that brings existing customers back into your sales funnel. With Opentracker’s automated customer journey reporting in real-time, you can see exactly where you’re losing customers on your site, then retarget them with online ads or use the data to improve that stage of their journey.
Whether you’re beginning to implement your mobile customer journey or want to supercharge your existing customer experience, Opentracker is an innovative platform that offers a comprehensive suite of features designed to automate customer journey reporting while equipping you with the insightful analytics and data you need to stay ahead of the competition.
Are you ready to embrace the power of mobile-first technology? Click to book a discovery call today!
Challenges All E-commerce Sites Face and How to Solve Them
Despite fierce competition, e-commerce sites tend to encounter a common set of challenges, especially when not properly planned and executed. Some site owners are so overwhelmed by these issues that they decide to suspend operations altogether.
These challenges however, are not unique to young e-commerce sites. Even the most established sites, including Amazon and eBay, still face these concerns on a daily basis. The difference between established sites and those that have left the game lies in the way these issues are addressed.
In this overview, we’ll
a) take a look at the most common problems e-commerce sites face and
b) how you can solve them.
Delivering a true omnichannel experience
Customers expect to have the option to shop and interact with their favorite retailers on different platforms. They want to be able to place an order on an e-commerce site, track the status of their order using a mobile app, call a customer service hotline to ask a question about their purchase, exchange it for another item at a brick-and-mortar store, leave a review on Yelp, and get regular updates on upcoming sales or promotions through email.

Source: Packaging Strategies
This approach to e-commerce is called an omnichannel experience. It allows customers to reach your brand whenever and wherever they wish. If your business isn’t moving toward offering an omnichannel presence, it risks getting left behind by the competition. Here are some steps you can take to form an omnichannel strategy:
- Identify key channels: If your company is just starting with e-commerce or is gradually scaling up its online presence, you may start with a few channels first. Identify the channels that your customers prefer. These may include phone, email, social media (and live chat), messaging apps, or in-app communication. You need to integrate these channels and ensure that the content and tone of voice is consistent. You may even use chatbots to automate your responses to common customer inquiries.
- Use context to respond correctly: Your e-commerce platform has a wealth of data about customer transactions. Performing real-time analytics will help you determine the next steps to take whenever a customer gets in touch with your brand. For example, when an existing customer logs into your e-commerce site, the site should be able to access their purchase history, even the transactions made in-store, and come up with relevant suggestions.
Creating a true omnichannel experience may seem complicated, but this need not be the case. The best ecommerce platform for your business will be able to integrate with the different channels you’re already using and make customer data readily available for these channels to utilize.
Shopping cart abandonment
Abandoned shopping carts (where people put items in their cart but fail to check out) are relatively rare in physical stores but present a big problem when it comes to e-commerce. An abandoned shopping cart means lost opportunity costs. Most of the time, a high cart abandonment rate indicates a poorly-designed e-commerce site or unnecessarily complicated processes.
The good news is that you can reduce cart abandonment and get more of your customers to click on “Checkout”. These simple strategies will get you started:
- Increase the page load speed: One study shows that e-commerce conversion rates go down by 7% for every second delay in page loading. To reduce the page loading time, we recommend optimizing the images on the checkout page, removing unnecessary HTML code, or limiting social plugins.
- Implement an exit intent pop-up: An exit intent pop-up displays when detecting that a page visitor is about to close the browser tab. You may use this pop-up to offer incentive deals or discounts, or promote new items to keep the customer on the website.
- Send cart abandonment emails: Some customers abandon their shopping carts because of technical issues beyond their control and forget all about their transactions. Sending a cart abandonment email featuring high converting email copy will remind them of their pending purchase and give them an express lane to complete their orders. Send one email within one or two hours after the cart abandonment, then follow up after 24 hours if the customer still doesn’t push through with the purchase.
With so many competing options available, you need a compelling reason for your customers to stay on your website or come back and complete a transaction. Cart abandonment doesn’t have to mean the end of your relationship with your customer. When you handle cart abandonment properly, it will lead to higher revenue and better customer loyalty.
Keeping customers loyal and engaged
According to Forbes, attracting a new customer costs up to 5 times more than retaining an existing one. While we’re not telling you to abandon new customer acquisition, you need to rethink your customer retention strategy. At the very least, you should exert as much effort on keeping your customers loyal to your brand as you do on attracting new ones.
Building trust and loyalty among your customers isn’t something you can do overnight. The first step in establishing trust is to ensure that your customer service processes are efficient, from ordering to shipping to after-sales service. Even if you have a good product, you can’t expect your customers to stay loyal to it if your customer service is lacking.
Aside from providing superior customer care, you also have to engage your customers and keep them interested in your business. Posting relevant articles to your company blog, for example, will help your customers identify market trends and position your brand as a thought leader. Publishing instructional content will allow your customers to get the most out of your product and solve the pain points that led them to your brand in the first place.
Loyalty programs are also a great way to build customer loyalty. Implementing a loyalty program achieves two goals. First, you get to reward your top customers for sticking with your business. Second, you encourage them to buy from your business more often or to refer you to their contacts, generating even more revenue and possibly converting them into repeat customers.
Attracting quality traffic and increasing conversions
Building a shiny new e-commerce website is the easy part of running an online business. Attracting quality traffic – users who are likely to make a purchase – is more challenging. According to conversion rate optimization firm Invesp, the global website conversion rate is around 4.3%, while for the U.S, only 2.63% of site visits result in conversions.
E-commerce conversion rates vary across countries and industries. If your business is performing at a lower rate than the average site, it needs to attract customers who are ready and willing to buy. You may try the following strategies to increase conversion:
- Focus on high-converting channels: A significant number of non-converting visits come from channels populated with customers who are not interested in your product or are not in your target market. Social media, for instance, is not so efficient at getting customers to convert because it casts a very wide net. An email newsletter, on the other hand, is relatively effective because it reaches people who have previously indicated an interest in your brand, either by downloading content from your website or signing up to your mailing list.
- Promote your best-selling products: Within your site, different products will have different conversion rates. Using a page analytics tool will help you identify which product pages have the highest traffic and the most conversions. These types of insights can help you determine the products you need to promote. For example, if you run a lighting fixture store and your page insights say that chandeliers perform better than pendant lights, you may feature chandeliers prominently on your home page and enjoy higher conversions.
- Use long-tail keywords for improved SEO: If your customers can easily find you via Google, they are more likely to visit your website. Optimizing your website and product pages for long-tail keywords (specific phrases with more than two words) will attract customers who know exactly what they need. For example, the keyword “transistor radio” will lead you to the Wikipedia page on the subject, but the keyword “RCA portable AM/FM radio” shows this Amazon product page in the top three results because it is optimized specifically for that keyword:
Attracting traffic to your e-commerce site is good, but if your site visitors don’t make a purchase, you are not attracting the right kind of traffic. Focusing on high-converting channels, promoting your bestsellers, and optimizing your product pages for long-tail keywords will help you target visitors who are more likely to convert. This is referred to as the Quality-over-Quantity rule.

Choosing the right technology solution providers
Between two or more businesses offering the same type of product, the one that stands out is often the company that has chosen its technology solution providers well. Many online retailers encounter difficulties with growing their business because the solutions they chose were not easily scalable or because they engaged the wrong partners to manage their operations.
Technology is one of the bedrocks of business growth. You need to choose the right solutions for all facets of your business, such as collaboration, customer relationship management (CRM), order management and fulfillment, inventory management, website analytics, email marketing, and finance and accounting.
In this sense, “the right solutions” does not just mean software that offers all the bells and whistles. For small businesses, it may also mean integrations with existing software, user-friendliness, and low costs. For example, some businesses may need specialized bookkeeping software, especially if they handle large volumes of complex transactions. Others choose to start with cheaper Quickbooks alternatives for simpler transactions then upgrade when they can afford it and it becomes necessary.
In addition to choosing the right software, hiring the wrong partners for software maintenance and project management may adversely affect your growth. You may think you’re saving money by hiring someone with a very low cost, but in the long run, you may end up paying more for software repairs and data recovery on top of the sunk costs of system downtime. Select a partner that has a proven track record in implementing the solutions you need and is able to provide assistance as soon as you detect an issue with your solutions.
Conclusion
Operating an e-commerce website brings challenges that are different from those you encounter while operating a physical store or another type of business. As your business expands, addressing these challenges will help you convert them into opportunities for generating more revenue and establishing customer loyalty.
The way that you deal with problems will determine the direction your business will take. Focusing on the customer, offering a true omnichannel experience, attracting quality traffic, and partnering with the right technology partners will help you take your business to the next level.
Author

Jimmy Rodriguez is the COO of Shift4Shop, a completely free, enterprise-grade ecommerce solution. He’s dedicated to helping internet retailers succeed online by developing digital marketing strategies and optimized shopping experiences that drive conversions and improve business performance.
Choosing Search Terms
In this article you will find information about:
- Search Terms and Best Strategies for Choosing Terms and Keywords
- The importance of choosing

- Opentracker Search Term tracking
- the right search terms & keywords
- How to choose search terms
- The role of words & language in your website
- Search terms and Search Engine Optimization (SEO)
- Improving your traffic by choosing the right terms
- Paying for keywords & search terms
- Tracking individuals by search term with Opentracker
- Search term pay-per-click (PPC) & ad campaign management

Search term keywords e.g. www.google.com/help.html
Search terms, also referred to as keywords, are the words, terms, and phrases that visitors use to find your site.
There are many ways to work with search terms and keywords. For example, selection of keywords when creating and managing ad campaigns. Sponsored listings are best managed by careful selection of search terms and keywords and everything that revolves around keywords which competing sites often bid for in terms of cents-per-click. Therefore you need to choose the right words to be effective.
A second example is building the correct words into your site’s text and including them in your site’s meta keyword list for search engine spiders to find and index your site. Besides that, it is also important to include relevant words in your page titles. Building the correct phrases and terminology into your site will allow your site to come up as results in search engine queries. This process is known as search engine optimisation (SEO). Furthermore, research suggests that a very small percentage of internet surfers click on sponsored results. The majority of surfers are interested only in the actual search results. Therefore, it is important to include the right search terms, phrases, keywords, etc, in your site content. This will make your site easier to find.
With well-managed and ongoing efforts, your site will climb steadily higher in search engine results.
5 Key Email Marketing Statistics of 2020
If you want to improve your business, you need to look at email marketing statistics. Doing so allows you to see how customers feel, what they want, and you can learn how to adjust your business to their needs. From mobile usage to advanced email deliverability metrics, email marketing covers a wide range of information.
Keep these five statistics in mind for the coming year.
1. Mobile Usage
People use their phones to access the internet and to check their emails. However, how many people check their emails through phones compared to their other devices?
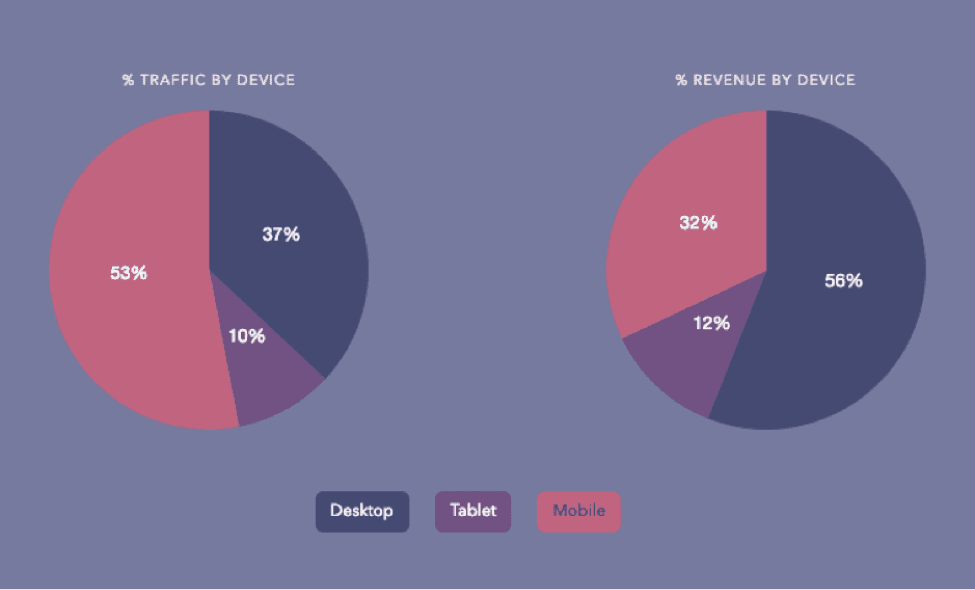
Interestingly, more than half of the users check their emails on their phones, but more than half of revenue comes from purchases on desktop. So what does this mean?
- Users prefer to check their emails on their phones.
- Customers use multiple devices during the purchase process.
- People make more purchases on their computers.
These statistics show that customers will most likely use more than one device during the purchasing process. If this wasn’t the case, the statistics for checking and revenue would match up better. Due to this, you know that your emails need to display correctly for mobile users while providing an effective purchasing experience for other devices.
2. Days for Emails
Timing matters when it comes to email marketing. You want to send your emails on a day that will work for your customers. Some people receive emails throughout the week, so they could easily miss your email if you don’t send it on a day that works for them.
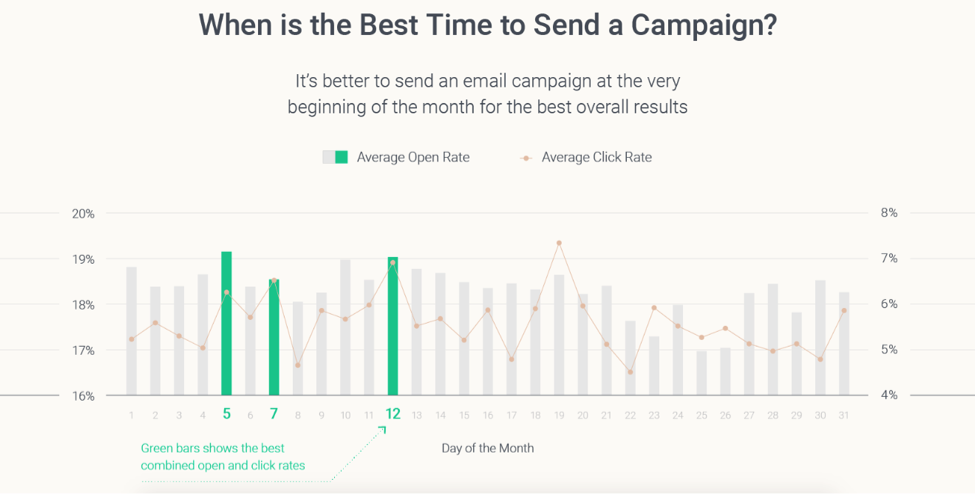
As you send emails closer to the start of the month, you will receive higher open and click rates. This means that customers will open your emails and they will click on the links inside. This gives them further interaction with your company and increases the odds of them making a purchase.
Keep in mind that you should consider other aspects of time when it comes to sending your emails.
3. Times for Emails
The time of day matters when it comes to sending emails. You want your customers to receive them at a time when they will most likely check their inbox. This will help you to find a time when they can see and open your emails. If they receive hundreds of emails a day, then yours could easily get drowned out by others.
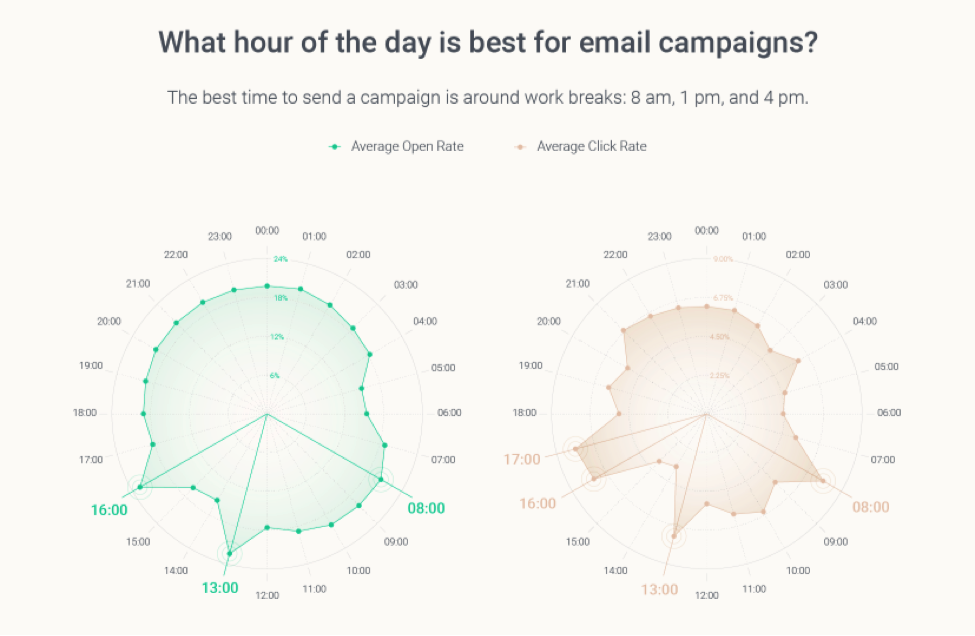
As you can see, 8:00, 13:00 (1:00 p.m.), and 16:00 (4:00 p.m.) bring in the highest numbers for open and click rates. If you consider people with a 9-to-5 job, this means that people check their emails before work, during their lunch break, and right before they go home.
The days and times may vary depending on your audience. While these stand as general guides to help you find the right time, you should test it out for yourself. By testing it, you can find more data that directly applies to your customers so that you can find the right email time for them.
4. Why Customers Open Emails
People don’t open every email that they receive. However, there are reasons why they will open emails, so you need to find out why people open emails.
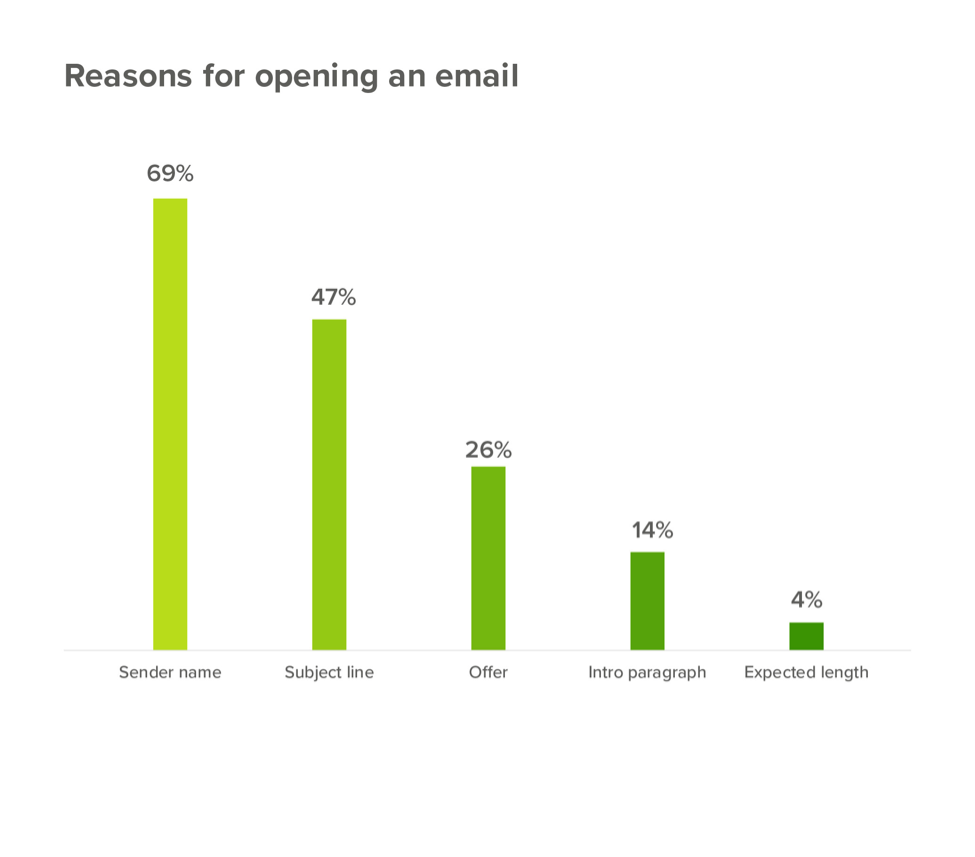
The name of the sender, the subject line, and the offer stand as the three biggest reasons why customers will open their emails. This makes sense when you consider the reasons.
- The sender name lets them know if they can trust the person.
- The subject line tells them the information so they can decide if they’re interested.
- An offer gives them an incentive to read the email.
This means that you need to gain the trust of customers, give them relevant information, and give them an offer. Try to hit these key points whenever you send out email campaigns to your customers.
While you want to benefit from email marketing, you want to provide something that benefits your customers. You could try some easy little tips and hacks for email marketing that your customers would read your email.
5. What Bothers Customers
While you want to appeal to customers, you also want to avoid anything that customers don’t like. Negative impressions can have a lasting impact on customers, so you want to do what you can to make your email marketing as good as possible.
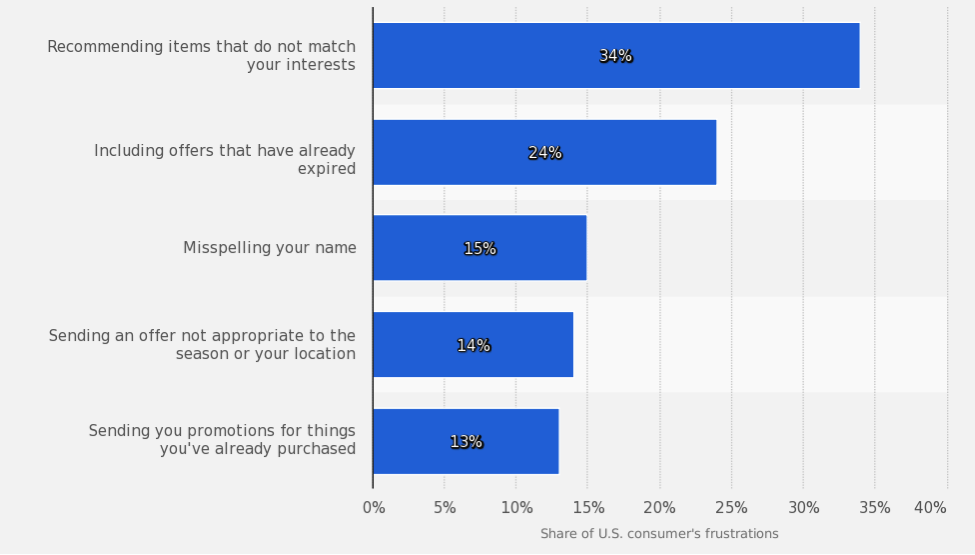
This image points out five major mistakes that you should avoid when it comes to your email marketing. By looking at these points, you can figure out what will keep customers satisfied.
- Optimize recommendations to make them as accurate as possible.
- Double-check the offer for expirations or mistakes.
- Spell the customer’s name correctly.
- Make sure the customer doesn’t already have the item.
This will help you to avoid frustrating customers so you can avoid losing them. As you do so, you can provide them with an excellent email experience and keep them as a returning customer.
6. Conclusion
Email statistics can help you to improve your marketing strategy. Statistics show you how customers behave so that you can figure out what they want. As you provide for the needs of your customers, they will want to interact with your business. Continue to build trust with your customers by providing them the information and services that they want.
Third-Party Cookies Vs First-Party Cookies
What is a (third-party) cookie?
A cookie is a small bit of text placed on the hard drive of your computer by the server of a website that you visit. The cookie is placed there for the purpose of recognizing your specific browser or remembering information specific to your browser, were you to return to the same site.
All cookies have an owner which tells you who the cookie belongs to. The owner is the domain specified in the cookie.
In “third-party cookie”, the word “party” refers to the domain as specified in the cookie; the website that is placing the cookie. So, for example, if you visit widgets.com and the domain of the cookie placed on your computer is widgets.com, then this is a first-party cookie. If, however, you visit widgets.com and the cookie placed on your computer says stats-for-free.com, then this is a third-party cookie.
Opentracker provides services that allow the companies and websites to track their visitors with first-party cookies.
Growth of third party cookie rejection
Reports and research on the subject of website tracking tell us that the rejection of third-party cookies is growing. Increasing numbers of people are either manually blocking third-party cookies, or deleting them regularly.
That is why Opentracker utilizes 1st party cookie technology.
The cookies being deleted / blocked are third-party party cookies, as opposed to less problematic first-party cookies.
How many people or software tools delete third party cookies? The numbers given can be as high as 40%. If you count that many anti-spyware applications and default privacy settings also block 3rd party cookies, then it is possible that a high percentage of cookies are being blocked.
Blocking and deleting cookies
Why do far fewer people block first-party cookies? It is estimated that a very low percentage of people block first party cookies, less than 5%. The reason for this is primarily that it is very difficult to surf the internet without accepting these cookies. First party cookies are necessary in order for you to be recognised as an individual. Any site that you login to as an individual requires a way of identifying you as “you”. Hotmail, Yahoo, Gmail, online banking, ebay, Amazon, etc.
Additionally, anti-spyware software and privacy settings do not target first-party cookies.
 We use cookies to keep track of long-term visitors. These visitors remain anonymous, the point is to be able to see who returns, if and when, for example, for conversion analysis.
We use cookies to keep track of long-term visitors. These visitors remain anonymous, the point is to be able to see who returns, if and when, for example, for conversion analysis.
We use first party cookies as our first line of analysis, and ip number with user agent as the secondary line. AOL users are identified more specifically because their ip number changes with every click.
What actually happens when cookies are blocked / rejected?
1st party cookies: it is very hard to login anywhere
3rd party cookies: no adverse effects to surfing
Q: How does this affect tracking systems, when people block / delete cookies?
A: All visits will still be recorded, but a person who has deleted the cookies will not be recognised as the same (returning) visitor.
When cookies are in place, and not blocked or deleted, total visitor counts will remain comparatively low. If a person constantly deletes cookies, they will be counted as a new “unique” visitor with every subsequent visit.
Conclusion
In response to these trends, the first step is to find out if the statistics that you collect utilise first-party or third-party cookies. Ask your statistics or tracking company. Asking questions usually leads to more questions, always a good thing when it comes to gathering and analysing data.